Get ahead in Generative AI with an advanced prompt engineering platform for teams
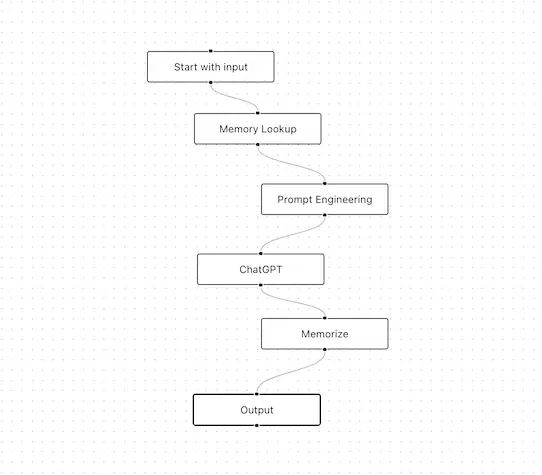
Simple interface for prompt engineers to create, test, and change prompts .
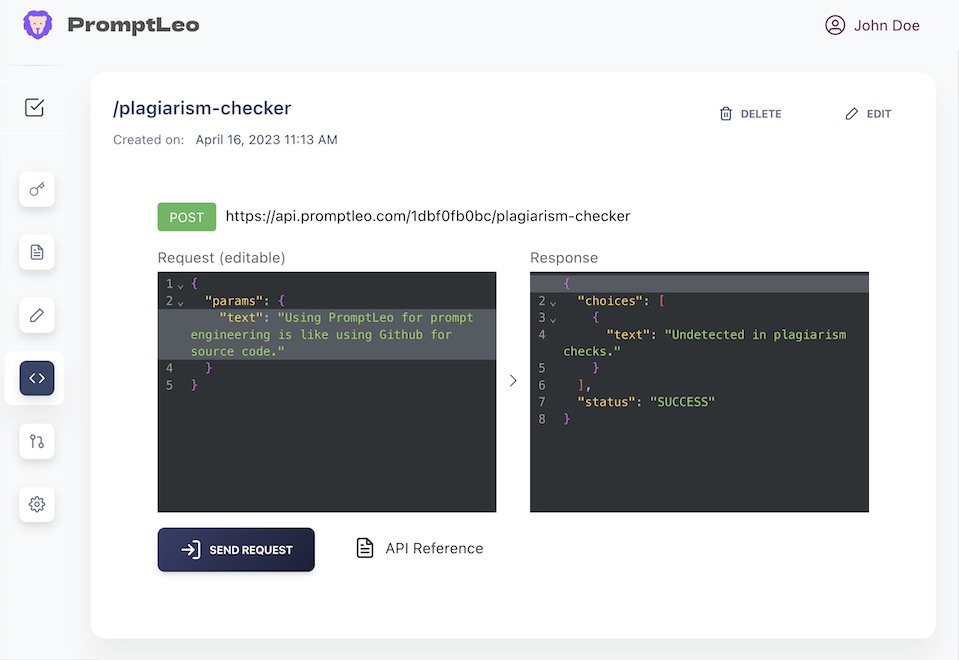
Bring Generative AI to your team. Integrate into daily workflows.
No need to store your prompts in text files. No more copy-pasting. Better teamwork.
new_releases
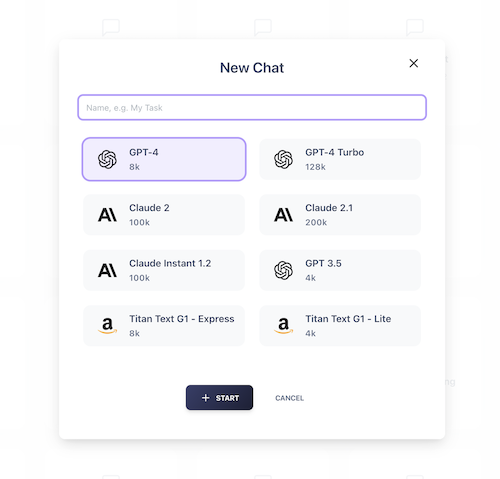
Reuse prompt templates
task